Hejo,
Tak, wiem, nie było mnie tutaj trochę czasu, niemniej nie traciłem (aż tak bardzo) czasu i wkręcałem się bardziej i bardziej w świat obsługi baz danych za pomocą czystego kodu, już stricte pod to, by praktykować wiedzę nabytą teoretycznie. I wiecie co? Jestem zadowolony, a tym wpisem ugruntuję sobie trochę już to, co wiem. Nie będę ukrywać, że wpisywanie czystych komend bez GUI sprawia, że czuję lekką satysfakcję z tego, że to, co właśnie wklepuje wychodzi już prosto z mojej głowy. Dobra ścieżka do tego, by zostać nedrem, co nie?

Patrzcie jaki jestem dowcipny ^_^
Okay, zaczynajmy!
Na wstępie zaznaczę, iż będę posługiwać się bazami danych, które tworzyłem albo samemu, albo korzystałem już z gotowców przygotowanych przez moich pośrednich nauczycieli (link do źródła podam oczywiście na końcu wpisu). Program z jaki korzystam przy wpisywaniu komend to nadal ten sam Apache Module czyli XAMPP, a wszystkie operacje, jakich wykonuję na zdalnym serwerze pochodzą prosto z shella.
ZAKŁADANIE BAZY DANYCH
Tutaj sprawa jest niezmiernie prosta. Po zalogowaniu się na nasz serwer komenda jest żywcem wyjęta z języka angielskiego (jak zresztą cały MySQL):
create database nazwa_twojej_bazy_danych;
Aby zobaczyć z jakimi bazami danych mamy styczność na zalogowanym serwerze możemy posłużyć się klauzulą:
show databases;
aby połączyć się z interesującą nas bazą używamy prostej komendy:
use nazwa_interesującej_nas_bazy_danych;
aby utworzyć tabelę w wybranej przez nas bazie danych używamy komendy:
create table moje_gry (id int primary key auto_increment, tytul varchar(20), platforma varchar(20), gatunek int);
Zwróć uwagę, że podczas kreowania tabeli określiłem od prawej do lewej jej tytuł, a następnie w nawiasach podałem nazwy poszczególnych kolumn oraz przypisałem im poszczególne zmienne. Myślę, że jest to zrozumiałe ale gwoli przypomnienia zamieszczę najczęstsze zmienne używane w MySQL:
int - liczba stała,
varchar(x) - 0-255 zmienne znakowe - wartość tekstowa o zmiennej długości, nie ma varchara ponad 255 znaków : )
datetime - data w formacie rrrr-mm-dd hh:mm:ss
date - sama data do przechowania w formacie rrrr-mm-dd
text - wartość tekstowa ponad 255 znaków;
skoro mówimy o tworzeniu tabel to warto również wspomnieć o ich usuwaniu. Robimy to za pomocą komendy:
drop table nazwa_tabeli;
Okay, teraz, kiedy mamy nowo co powstałą tabelę warto byłoby przyjrzeć się jeszcze raz jej opisowi. Do tego używamy komendy desc (z ang. description - opisanie):
desc nazwa_tabeli;
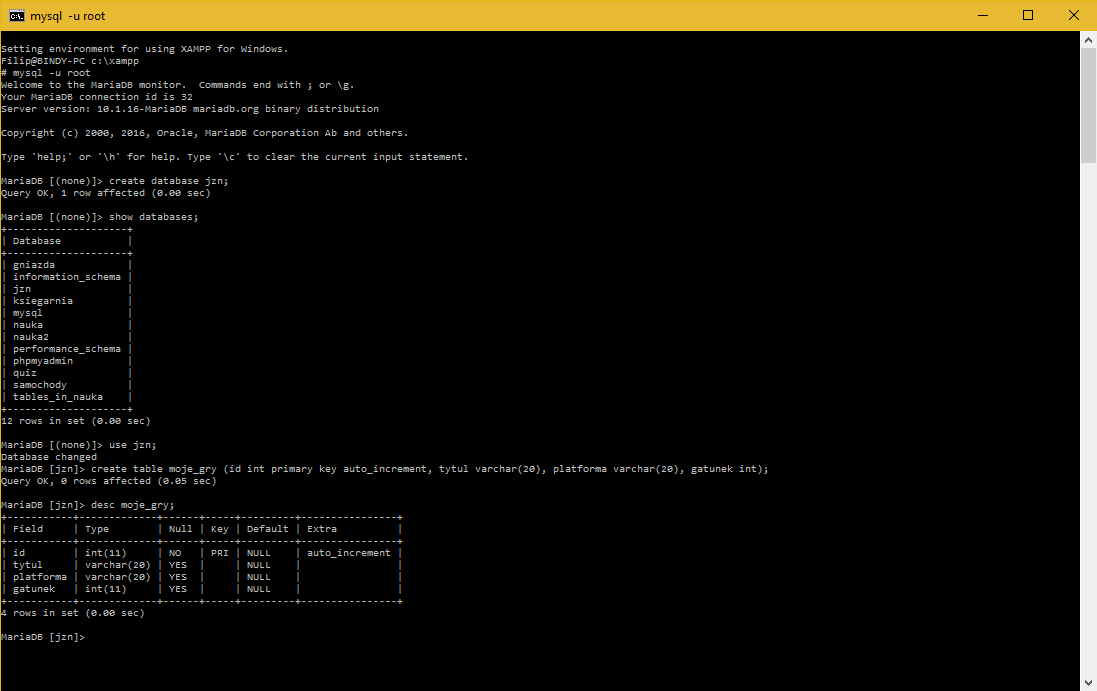
Okay. Teraz, kiedy posiadamy tablę wypadałoby umieścić w niej jakieś dane. Pamiętamy z ostatniego posta dokładnie, że używamy do tego klauzuli wstawiania insert into. Pozwólcie, że uzupełnię tabelę, a zapis z tego umieszczę na screenie pod tym zdaniem :)

Okay, jak widzicie na screenie powyżej za pomocą klauzuli insert to uzupełniłem ją danymi. Jeżeli jesteś uważny zwrócisz również uwagę na to, że miałem problem z ostatnim tytułem - nie byłem do końca przekonany na jakiej platformie wydano świetną grę pt. "God of War 3".
Następnie prostym selectem obejrzałem wszystkie * wstawione przez siebie rekordy.
select * from nazwa_tabeli;
Oczywiście jeśli będziemy chcieli wyciągnąć poszczególne dane, takie, jak tytuł samej gry nic nie stoi na przeszkodzie. Wiem, że pisaliśmy o tym wcześniej, dlatego nie chce się zbytnio cofać do tego samego. Gwoli prostego przypomnienia rzucę tutaj jeden ze wcześniejszych SQL rozkazów:
select tytul, platforma from moje_gry where platforma like '%360';
Tak, użyłem tutaj również komendy like, którą również poznaliśmy wcześniej (o ile pamięć mnie nie myli EDIT: nie, nie myli).
Należy również zwrócić uwagę na komendę IN (ang. w) - pozwala nam ona wyciągnąć dane rekordów, które niekoniecznie występują po sobie:
select * from nazwa_tabeli where id in (2,4,6);
O! Właśnie przypomniało mi się, że tak naprawdę God of War 3 było tytułem ekskluzywnym dla platformy Sony! Warto zaktualizować te dane:
update moje_gry set platforma='PS3' where id=6;
Proszę bardzo. Pamiętajcie jednak, że bez where zaktualizowalibyśmy całą kolumnę o tę jedną wartość!
Wiecie co? Może dodamy jeszcze jedną kolumnę do naszej tabeli. Wpiszemy tam koszt każdej z gier, a co! Dokonamy tego kolejnym poleceniem alter table (alternate z ang. w tym przypadku będzie oznaczać zmienny lub przemienny) oraz dalej add (z ang. dodać):

Zwróćcie uwagę na to w jaki sposób dodaje się nową kolumnę. Jest to klauzula, która jednocześnie musi opisać zarówno nazwę nowej kolumny jak i przypisać jej zmienną, stąd kod wygląda właśnie w taki sposób:
alter table moje_gry add cena int after platforma;
Chciałem, aby kolumna cena była koniecznie po kolumnie platforma, stąd after (z ang. po) w komendzie :)
Następnie aktualizowałem poszczególne rekordy używając przy tym sztuczek z wcześniej omawianym between oraz matematycznymi znakami większe bądź równe :)
następnie selectem potwierdziłem gotowy efekt.
To co, teraz wypadałoby zsumować pieniądze, jakie bym zarobił, gdyby udało mi się sprzedać każdy z tytułów? Służy do tego kolejna, bardzo przydatna klauzula sum (z ang. suma):
select sum(cena) from moje_gry;
MySQL mówi mi, że dostanę za nie 364 pln.. Co by było, gdyby wynik był podany w paru miejscach po przecinku, np. 364,4123? Na to również jest odpowiednia komenda o nazwie round(). Jeżeli chcielibyśmy zaokrąglić wynik do dwóch miejsc po przecinku (a tak właśnie podaje się u nas wartości w złotówkach) to komenda wyglądałaby w taki sposób:
select round(sum(cena),2) as cena from moje_gry;
Użyłem tutaj aliasu as (z ang. jak) po to, by wartość podana w kolumnie miała ładniejszy i bardziej przystępny opis.

Zwróćcie uwagę na to, że popełniłem wcześniej w zapisie jeden błąd, przez który MySQL się zbuntował. To również stanowi o sile tego języka.
Okay, spoko! Wyobraźmy sobie teraz, że chcemy obliczyć średnią wartość naszych gier. Używamy do tego komendy avg (z ang. average - przeciętny):
select avg(cena) as srednia_cena from moje_gry;
Dodatkowo chcielibyśmy policzyć ilość naszych pozycji sugerując się tylko liczbą rekordów. Używamy wtedy komendy count(1) (z ang. count oznacza liczyć, niektóre podręczniki mówią, żeby zamiast 1 wstawiać *, jedynka w nawiasie sugeruje odpowiednią kolumnę w tabeli - w tym przypadku będzie to kolumna pierwsza, najbezpieczniejsza, bo praktycznie zawsze jest id danej tabeli):
select count(1) from moje_gry;
Dodatkowo możemy policzyć średnią z gier, które są warte więcej, niż 50 zł:
select avg(cena) from moje_gry where cena>50;
Wszystko fajnie, wiemy jak policzyć rekordy, jak wywołać średnią liczbą oraz sumę, a jakby usunąć jeden z rekordów? Nic trudnego.. Przychodzi nam z pomocą słowo wszystkim nam znane delete:
delete from moje_gry where id=1
Należy pamiętać, iż gdybyśmy nie użyli where to MySQL skasowałby wszystkie rekordy.. Tak.. Wiem..
CIEKAWOSTKA - w MySQL numery id są przypisywane na stałe danym rekordom. Jeżeli usunęliśmy pozycję 1 o ID 1 to ten numer już nigdy nie pojawi się w tej konkretnej bazie danych, nawet, jeśli przywrócimy tego pracownika ponownie komendą insert to. Wtedy zostanie mu nadany nowy ID. Jest to logiczne, ponieważ dziwnie byłoby wstawiać np. tytuł nowej gry w miejsce sprzed 5 lat, prawda?
##### ŁĄCZENIE TABEL ORAZ ICH GRUPOWANIE ####
Zacznijmy może na odwrót, w kontrze do tego, co zrobiliśmy wyżej, także:
CIEKAWOSTKA - jest wzór na łączenie tabel. Wygląda on następująco:
n-1
gdzie n = liczba tabel, jakie chcemy połączyć.
Co on oznacza? Jeżeli chcemy połączyć dwie tabele (nawiązać pomiędzy nimi relacje), to będziemy musieli opisać MINIMUM jeden warunek określający te relację. Jeżeli będziemy łączyć trzy tabele to warunków będzie już wtedy potrzeba MINIMUM dwóch itd. Reasumując: n-1 da nam zawsze minimalną ilość warunków do opisania po klauzuli where. Pamiętajcie jednak, że trzy tabele można równie dobrze połączyć nawet i piętnastoma warunkami ; )
A teraz zajmiemy się prostym łączniem tabel na zasadzie relacji. W tym celu szybko zbuduję drugą tabelę w mojej bazie.

Zwróćcie uwagę na miejsca w których MySQL się buntował. Prześledźcie kod i zrozumcie dlaczego (tak, w moim przypadku w 95% przypadków są to literówki).
Wartym zwrócenia uwagi jest również fakt, iż dany plik.sql ze stworzoną przez nas tabelą możemy zaimportować do naszej bazy danych poprzez polecenie source. Kod będzie wyglądać wtedy w taki sposób:
source c:/users/filip/downloads/piesek2.sql (nie pytajcie o nazwę pliku *.sql)
----dla ambitnych----
Okay, warunki łączenia dwóch (i więcej) różnych tabel poznaliśmy we wcześniejszych wpisach, teraz chciałbym zająć się podobnym zagadnieniem ale będziemy łączyć dwie kolumny w jednej tabeli. Jest to troszkę trudniejsze ale bardzo ułatwia życie. Powiedzmy, że chcemy przypisać wszystkie tytuły gier do ich gatunku, zakładając, że id gry to faktycznie odpowiedni dla nich gatunek. Taki kod wyglądałby następująco:
select a.tytul as tytul, b.gatunek as gatunek from moje_gry a, moje_gry b where b.gatunek=a.id;
To, co zrobiliśmy to poinformowaliśmy w komendzie MySQL, żeby traktowała tabelę moje_gry jako dwie osobne tabele. Umożliwił to właśnie zapis dzięki aliasom w tym momencie:
from moje_gry a, moje_gry b
Oczywiście warto znać taki trik, jeśli będziemy musieli połączyć ze sobą wartości z dwóch kolumn w jednej tabeli :)
----dla ambitnych off----
Chcemy wyświetlić listę pierwszych trzech naszych gier razem z przypisanymi do nich gatunkami. Gwoli przypomnienia będziemy korzystać z dwóch tabel, które wcześniej stworzyliśmy (moje_gry, gatunek) w bazie danych, którą również stworzyliśmy (jzn):

Jak widać na załączonym shocie użyliśmy komendy w której zastosowanie znalazły zarówno aliasy, określenie relacji pomiędzy kolumnami z dwóch tabel oraz porządkowanie domyślne (ascending) do trzech pierwszych wyników. Fajnie, co nie? : )
-------------
Okay, teraz pora na polecenie grupujące. Co jeśli chcielibyśmy pogrupować dane w tabeli inaczej, niźli są pogrupowane aktualnie? Powiedzmy, że chciałbym ustawić gry wg. mojej klasyfikacji. Nic trudnego, tutaj będzie potrzebna komenda field():
select * from moje_gry order by field (id, 5,1,2,3,6,4);
zauważcie, że po field (z ang. pole) wpisujemy w nawiasie nazwę kolumny, którą grupujemy, a potem kolejno nazwy poszczególnych rekordów w tej tabeli :)
Komendy field() możemy używać również w bardziej skomplikowanych zapytaniach:
select a.id, a.tytul, a.platforma, g.nazwa from moje_gry a, gatunek g where a.gatunek=g.id order by field (a.id 5,1,2,3,6,4);

-----------------------
A teraz poeksperymentujmy! Czy wiecie, że można tworzyć tabelę poprzez zapytania?
Przykład: Stwórz nową tabelę w której zawarte będą wszystkie tytuły gier tylko z PS3? Jasne, możemy tworzyć nową tabelę i mozolnie wklepywać kolejne rekordy. Szczęśliwie możemy również jedną prostą komendą skopiować wszystkie potrzebne nam dane w postaci nowej tabeli! Potrzebna będzie nam tutaj komenda AS (z ang. jako):
create table tytuly as select id, tytul from moje_gry where platforma='PS3';

Tak, dobrze widzisz - usunąłem tę tabelę na końcu :P
Wartą wspomnienia jest również klauzula VIEW. Jest ona odwrotnością kopii tabeli, jaką wykonaliśmy powyżej. VIEW jest reprezentacją danych z jednego miejsca bazy danych w innym miejscu bazy danych. Reasumując - jeśli pracujemy na tabeli stworzonej komendą VIEW mamy wpływ zarówno na nią, jak i na materiał źródłowy JEDNOCZEŚNIE. Po co ją stosować? Możemy utworzyć na stałe aliasy poszczególnych SELECTów, co mocno uprości nam pracę ale przede wszystkim możemy udostępniać naszą bazę danych innym osobom do edycji i decydować, co te osoby mogą z niej zobaczyć. Bezpieczeństwo przede wszystkim!
Póki co to na tyle. Niedługo czekają nas pytania zagnieżdżone oraz troszkę o optymalizacji wyszukiwania :)
Pozdrawiam : )
F.
Źródła mojej nauki to:
Polecam serdecznie!
Warto wpaść na ich website. Wiele wiedzy podanej w przystępny sposób!
Brak komentarzy:
Prześlij komentarz